Binder 2.0, a Tech Guide

Authors: The Binder project is comprised of many individuals within and outside of the core Jupyter team. A list of members that contributed to this post is at the end of this article.
Note: this post focuses more on technical changes in the Binder 2.0 reboot. For a post about user-facing features and future plans, see this eLife blog post.
We are undergoing a dramatic increase in the complexity of techniques for analyzing data, doing scientific research, and sharing our work with others. In early 2016, the Binder project was announced, attempting to connect these three components. A blogpost in eLife described a vision where scientists could specify dependencies along with a collection of Jupyter notebooks. Binder builds a Docker image from these dependencies, and provides a URL where any user in the world can instantly recreate this environment.
Want to see it in action? Click the button below.

With this post we are proud to announce the next version of Binder. It aims to be more modular, more flexible, more stable, faster, and more extensible than its predecessor. Powering this version of Binder is a collection of tools in the Jupyter ecosystem. Since being released, the Binder project has learned many things about implementing fast, flexible online deployments. In addition, its vision has expanded to include not only Jupyter notebooks, but many other computational workflows. You can access an open beta version of this deployment here:
You can find a list of sample repositories to learn how to create “Binder”-ready repositories here:
You can also see what the Binder community has been up to in creating their own repositories by checking the GitHub Binder topic:
https://github.com/topics/binderGive it a shot, build some repositories, and importantly, tell us what could be improved on our GitHub repo. Below we’ll describe a bit about what’s new.
What’s new?
First off we’ll describe how the experience will change for users. The short answer is: not much. The goal of Binder is still enabling you to intantly create interactive and shareable repositories. We’ve completely rebuilt the backend of Binder, but we’ve made minimal changes to the front-end user experience.
The biggest difference you should notice is that Binder is both faster and more stable. You’ll still be able to generate Binder links from a git URL from a single web-page. However, there are a few key differences:
New Default Environment
Old versions of Binder were based off of a Docker image that contained a fairly heavy computational environment. The new Binder deployment makes minimal assumptions about what environment you want installed, by default the only thing that will be installed is the Jupyter Notebook and Python 3. This means you’ll need to be more expressive in the dependencies you include in your dependency files. For example, if you want numpy or matplotlib, you should specify them in a requirements.txt or environment.yml file. Since you’re explicitly listing your requirements it makes reproducing your work more reliable, and allows the Binder infrastructure to change more freely without breaking your repository code.
New URL structure
The new URL structure for Binder follows the following convention:
https://mybinder.org/v2/gh/<org-name>/<repo-name>/<branch|tag|hash-name>?filepath=<path-to-file>For example, below is the URL for a basic Binder-ready Python 3 repository, it includes basic information about the repository:
https://mybinder.org/v2/gh/binder-examples/requirements/masterYou can also specify parameters that do things like point users to a particular file or initialize a user-interface. For example, the following URL starts JupyterLab once users click the link:
https://mybinder.org/v2/gh/binder-examples/jupyterlab/master?urlpath=labIn each case, note the gh at the very beginning — this specifies that the git URL exists on github.com. It is possible to build new URL parsers for other online repositories such as BitBucket, osf.io, or any other provider. We are currently focusing on Git and GitHub, but nothing prevents Binder from being compatible with other kinds of content providers. Shortly before this blog post we added support for arbitrary git URLs to binderhub, so watch this space.
Specify a specific branch / tag / commit
Also notice that in the URL above you can specify a branch, tag, or commit hash for the Binder image. This allows you to ensure that a Binder image will always remain the same (if you specify package versions properly). This is a crucial step for reproducibility and maintaining consistency in how users experience the files in your repository.
Notice that in the URL above you can specify a commit hash or git tag for the Binder image. This hash is unique to the state of the code at the moment that the commit was made, ensuring that Binder can rebuild the exact same environment any time. Note that if authors don’t want to guarantee the same reproducible environment, they can specify a branch and BinderHub will resolve it to the latest commit hash before building the environment.
Binder auto-building
When a git repository is launched, Binder will now check whether an image has already been built for that repository at the same commit hash. If it has, then Binder will skip the building process and take you straight to a JupyterHub instance that serves this image.
If the image hasn’t been built, then it will automatically be generated before sending the user to JupyterHub. The only difference will be the amount of time it takes before entering the JupyterHub environment. This means that authors no longer need to explicitly build their Binder images when they update a branch. The next time someone clicks a Binder link, it will happen automatically. If you don’t want this behavior, be sure to point Binder to a specific tag or commit hash, rather than a branch name or tag. For example, here’s a Binder URL that will always point to the same commit hash:
https://mybinder.org/v2/gh/wildtreetech/explore-open-data/binder20-elifeWhile this URL points to a branch, and will thus be re-built each time a new commit is made to that branch:
https://mybinder.org/v2/gh/wildtreetech/explore-open-data/masterMore options for dependency files
Users often want to specify a computational environment that is more complex than a simple list of Python requirements. While this is possible by specifying a Dockerfile, it’s often an overly-complicated solution to this problem. Binder now uses repo2docker to build a Docker image from your repository. This makes it possible to specify a more complex environment with text files. For example, you can use an apt.txt file to install packages with apt-get, or use a file called postBuild to define shell commands that are run before generating the Docker image (e.g. for downloading some data or running scripts). See the repo2docker documentation for a list of files that are supported with Binder.
For a selection of examples that show off how to specify dependencies take a look at the example gallery: https://github.com/binder-examples
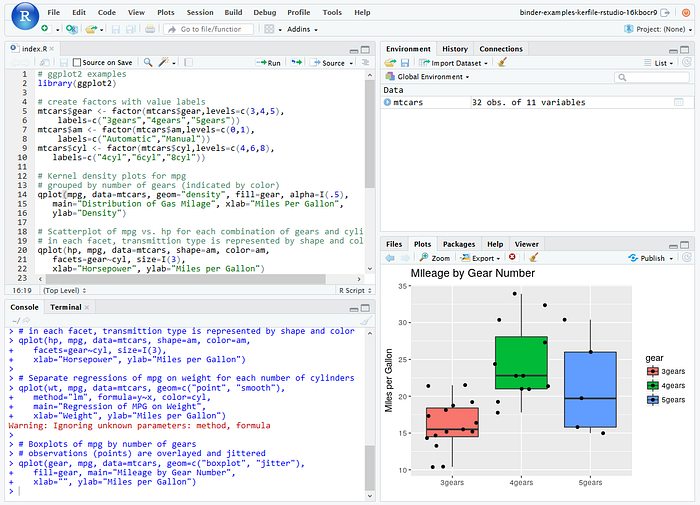
More user interfaces
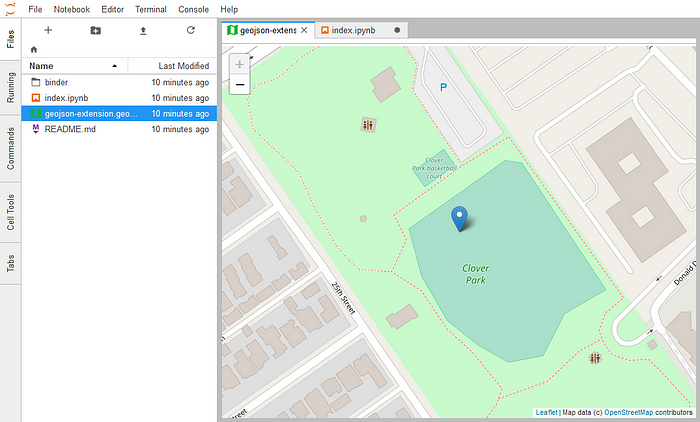
mybinder.org/v2/gh/binder-examples/jupyterlab/master?urlpath=lab`The previous iteration of Binder only supported the classic Jupyter Notebook user interface, while the new deployment will additionally support RStudio and JupyterLab. Because of the extra build configuration files specified above, you can also utilize more tools in the Jupyter widgets ecosystem, such as the RISE plugin for interactive presentations or the appmode plugin to generate interactive apps from your repository. We also welcome contributions to add support for other user interfaces.
More online repository providers
While GitHub is a fantastic repository of open-source code, it’s not the only repository. The new Binder deployment makes it straightforward to adding support for new sources of code (for example, GitLab, the OSF, or even non-git codebases). Currently GitHub is the only supported source for code, but we welcome contributions enabling support for new sources.
We’re excited about this next step in Binder’s development, and hopeful that we can build a community around this powerful set of tools. Don’t hesitate to open an issue or pull request on our GitHub repository, or to reach out via our Gitter channel. We look forward to seeing what comes next, and to continue enabling reproducible and open workflows in data science and research.
For developers
The next few sections are meant for developers interested in deploying their own Binder, or for those interested in the technical details behind the new deployment.
Tech components
The three main technical components behind the new Binder backend are:
- BinderHub, currently on display at mybinder.org and contained in the binderhub repository.
- repo2docker, a tool that converts a code repository into a Docker image with an environment specified via dependency files (e.g.,
requirements.txt). - JupyterHub, which hosts user instances with a server in the cloud. We use a distribution of JupyterHub that runs on top of Kubernetes.
For more information on the infrastructure behind Binder, see the documentation.
Kubernetes
Binder now also heavily relies on Kubernetes for scaling our image building service and the JupyterHub. Kubernetes is massively scalable and has a strong community of developers behind it. Moreover, Kubernetes is cloud-agnostic. It can be run on Google Cloud, Microsoft Azure, and AWS among others, as well as on your own bare metal hardware if needed. Because BinderHub is built to run on top of Kubernetes, you can deploy Binder off of any of these resources as well (see below).
Deploying your own Binder server
While mybinder.org will continue to exist as a public service, we hope to see new Binder deployments for many different use cases in the wild. One of our primary goals is to make it easier for users to deploy their own Binder servers. This is relatively straightforward by following the instructions on the BinderHub documentation, which are currently under active development to make ongoing improvements as the Kubernetes technology evolves. We’re continuously updating these steps to make them as clear as possible, so please don’t hesitate to open an issue or a pull request on our github repository and make suggestions.
We would love to see others deploy their own BinderHub servers, either for their own communities, or as part of a federated public service of BinderHubs.
Future development
This is the just the beginning of new features and improvements to Binder. We’re working hard to grow an open-source community around these tools, and we encourage issues, comments, and PRs on the BinderHub, repo2docker, and JupyterHub repositories. We look forward to growing the Binder ecosystem, and we’re excited to see all of the Binders that people design.
Acknowledgements (alphabetical order)
C. Titus Brown (UC Davis), Matthias Bussonnier (UC Berkeley), Jessica Forde (UC Berkeley), Brian Granger (Cal Poly), Tim Head (Wild Tree Tech), Chris Holdgraf (UC Berkeley), Andrew Osheroff (Google), Naomi Penfold (eLife Sciences), M Pacer (UC Berkeley), Yuvi Panda (UC Berkeley), Fernando Perez (UC Berkeley), Min Ragan-Kelley (Simula Research Laboratory), and Carol Willing (Cal Poly). The Binder project is currently being funded from a grant from the Moore Foundation.

