Binder + Zenodo: A how-to guide
Interactive and reproducible repositories powered by Zenodo and Binder.
When the Binder project was first launched, we imagined a world in which scientific scholarship and reproducibility could be carried out by the community using a fully-open stack of technology. We’re happy to say that this is now possible!

The BinderHub team recently added in support for building Binder links that point to Zenodo repositories. Zenodo is a general purpose open-access repository hosted by CERN that allows researchers to archive and apply a DOI to information that they put up on the web.
Zenodo has the ability to archive GitHub repositories, which means that you can archive the code, data, or reports that underly a scientific analysis and assign it a unique, citeable identifier. Now that BinderHub knows how to resolve a Zenodo identifier, you’ll be able to share Binder links that point to Zenodo and provide interactive access to your repository, letting readers reproduce results and interact with your analyses!
Here’s a quick primer for how to do this:
Step 1: Create a Zenodo account
First off you’ll need to create an account on Zenodo. You can
do so using a number of different log-in options.

Step 2: Create your Binder-ready repository on GitHub
Next, you should create your Binder-ready repository on GitHub. Binder uses pre-existing best practices in data science in order to infer and build the environment needed for your repository.
To make a repository Binder-ready, follow the instructions in the Binder docs.
Briefly, what you need to do is add the configuration files that define the environment needed to run your code. Once those files are in place, and you’ve added an analysis script (a Jupyter or R Notebook) that actually runs your code and displays the results, your repository is ready to build with Binder.
Step 3: Make sure your repository is ready to be published!
Once you create a DOI for your repository, it will be frozen in time — you won’t be able to easily update it. So double check that the repository builds properly with Binder and runs the way that you’d expect it to.
Make sure to launch a Binder from your repository and run the analyses you’d like others to run. If they produce the expected result from within a Binder session, then they’ll continue to do so for others (assuming you have pinned your versions and followed other best practices in reproducibility).
Step 4: Create a Zenodo DOI for your repository
Now that your repository is ready, you’ll connect Zenodo with GitHub to create a DOI for your repository. Remember that this will be unique to the current state of the repo — future changes to this repository won’t be reflected in the DOI.
We recommend following the GitHub Citable Code Guide which provides some best-practices for creating your Zenodo DOI for a GitHub repository. Click the image below to be taken to this (excellent) guide.

Once you’re done, you should have a Zenodo DOI badge
like the one below:

Step 5: Create a Binder link for your Zenodo DOI
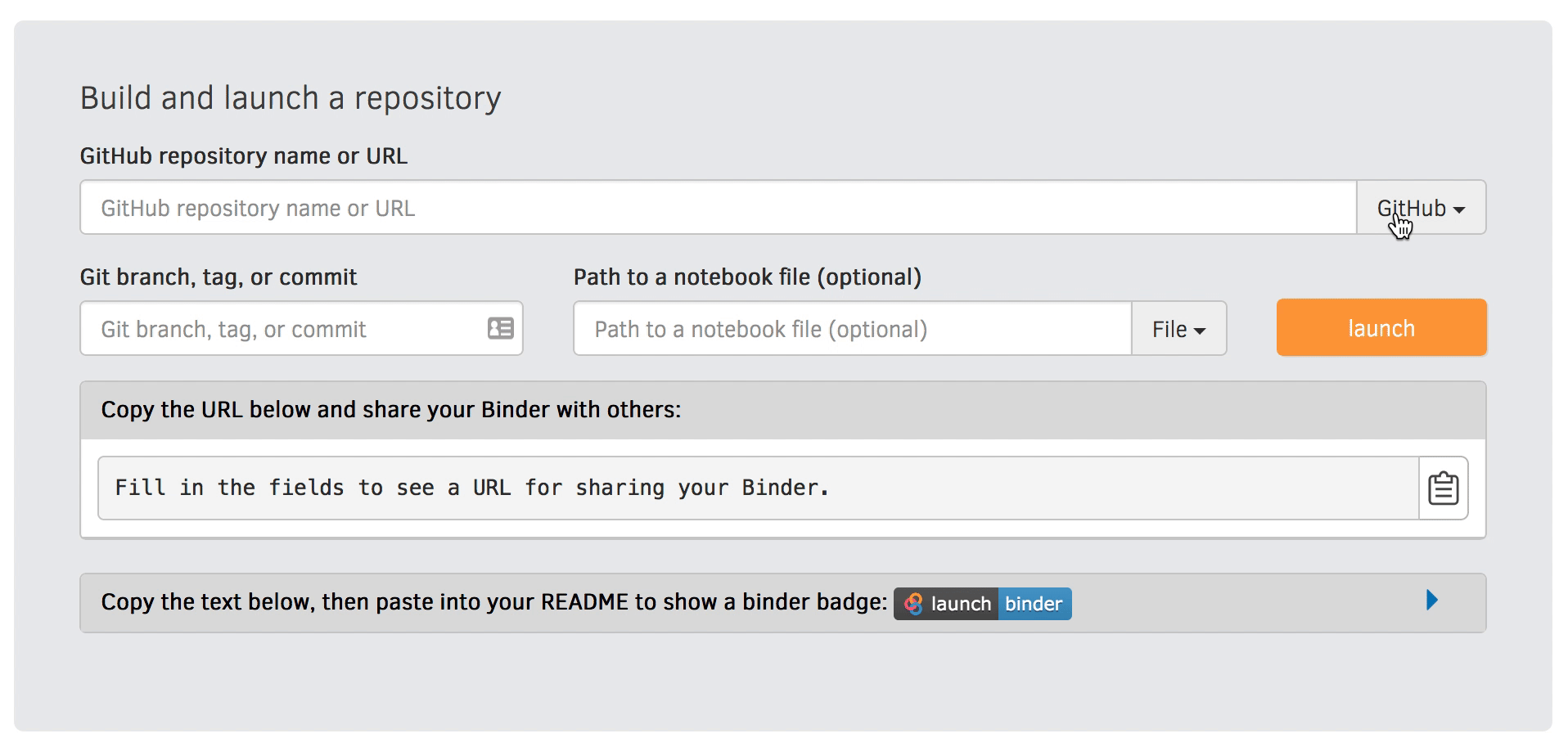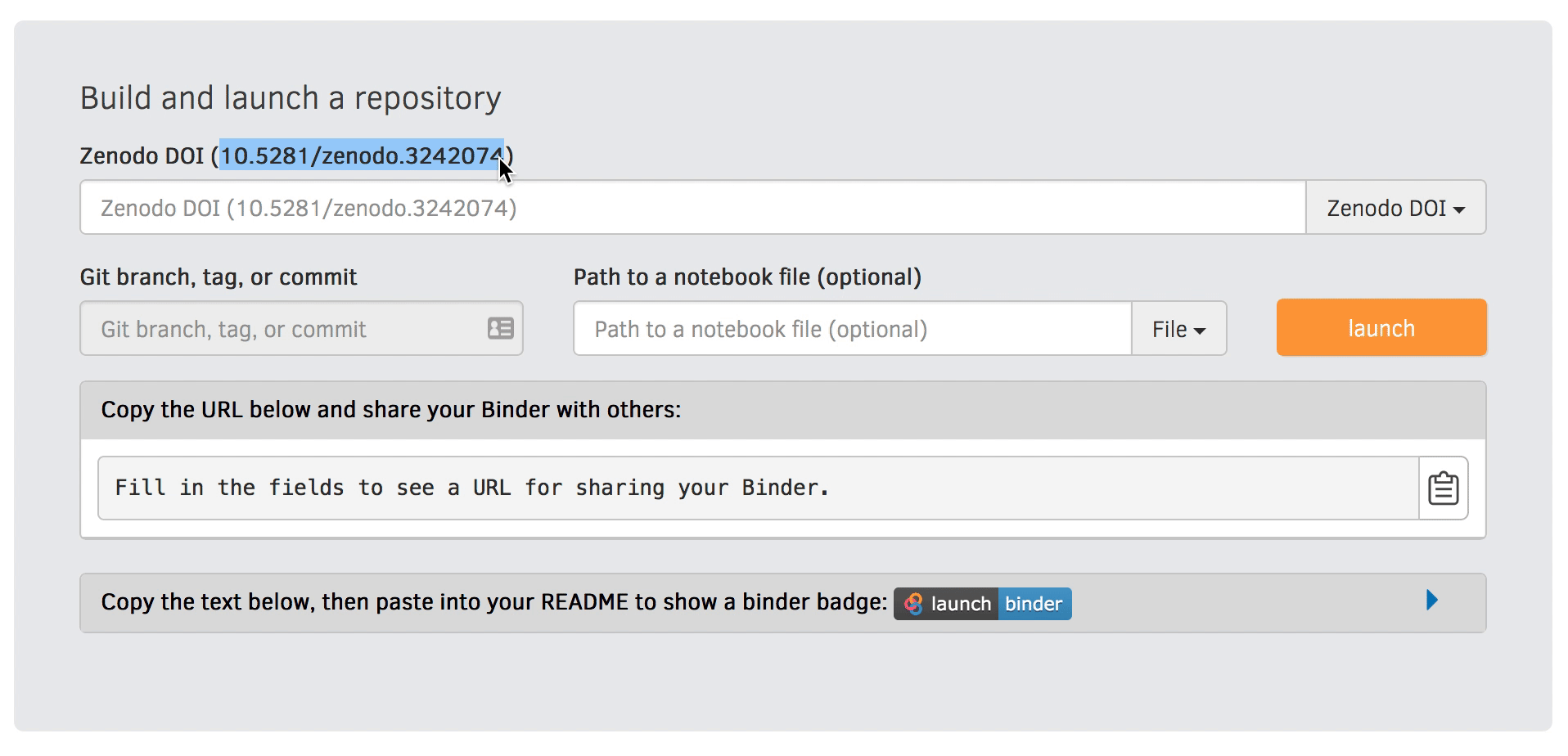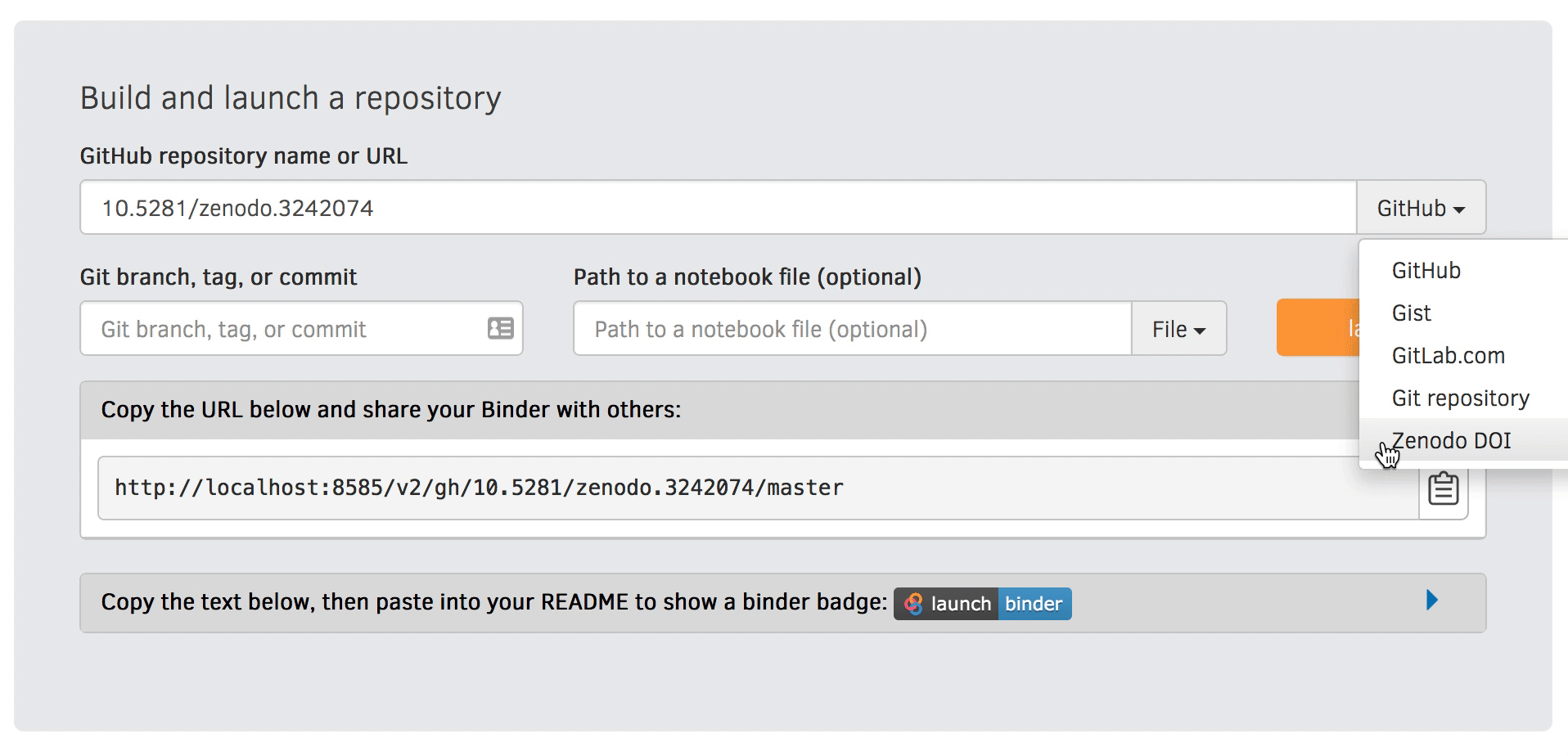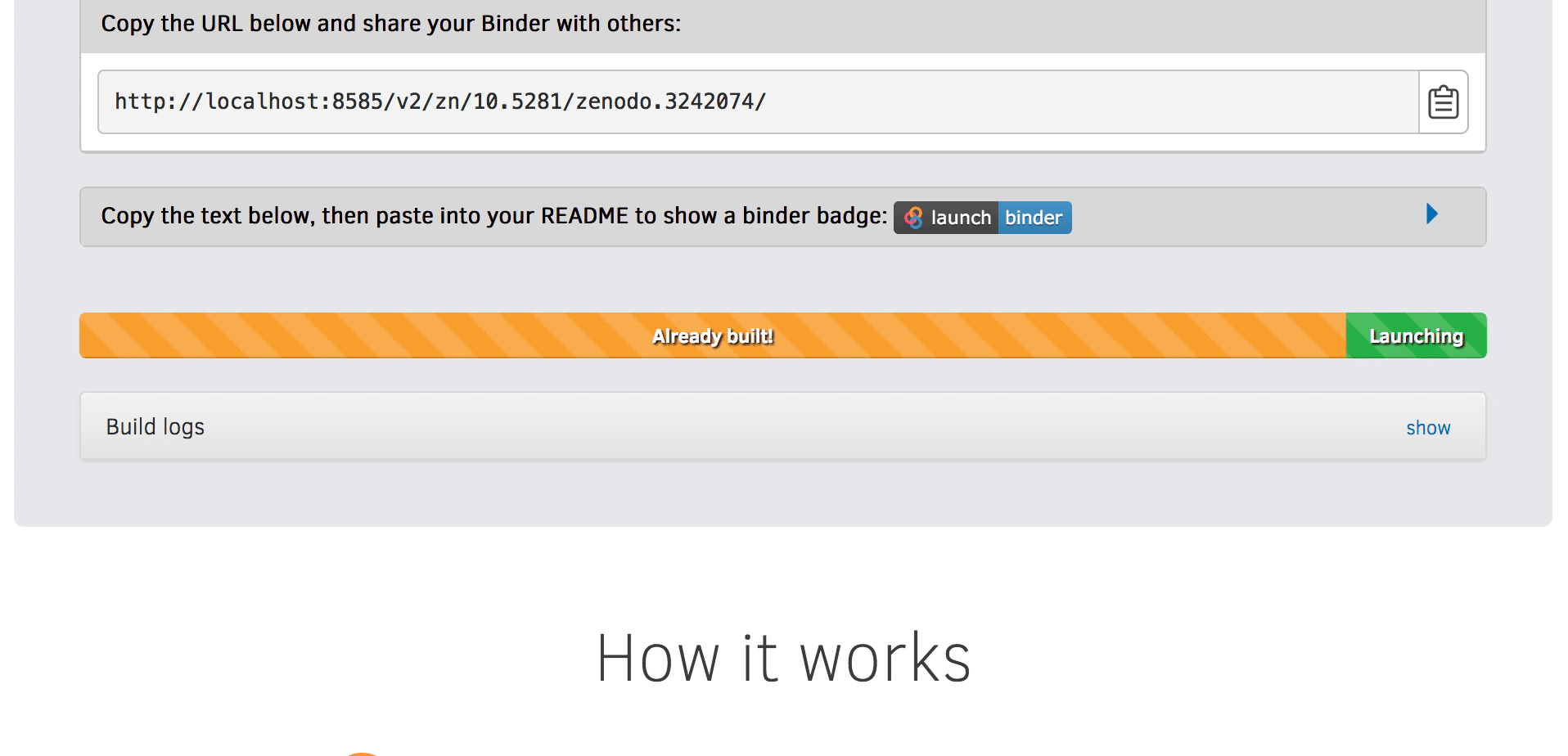
Finally, use your Zenodo DOI to create a Binder link that allows others to interact with and replicate your results. You can create a Binder link for your Zenodo record by heading to https://mybinder.org and filling in the form:
This will give you a link you can share with others as well as the Markdown and reStructured text snippets for creating a badge.
The link’s structure should look like this:
https://mybinder.org/v2/zenodo/<zenodo-DOI>For example, if your Zenodo DOI is 10.5281/zenodo.3242074 (corresponding to this zenodo repository), the Binder link for it would be:
https://mybinder.org/v2/zenodo/10.5281/zenodo.3242074/You can even pair this Binder link with your Zenodo DOI badge that
we showed above!

And that’s it! You now have an archived version of your analysis with a unique identifier. This identifier can be used in conjunction with BinderHub to allow readers to interact with your code and results!
Last minute update 🎉
A few hours before publishing this post we merged a contribution from Tom Morrell who works at CalTech’s library that allows you to launch records from CalTech’s Data Repository as well! For example a notebook to analyze traffic to the archive itself: https://mybinder.org/v2/zenodo/10.22002/d1.1250. You should also check out a quick response to this post from Lorena Barba, who describes her group’s approach to creating reproducible, citable bundles for figures in papers, and how Binder+Zenodo DOIs might fit into that workflow!
What’s next?
We are close to closing the loop of fully reproducible computational environments for scientific publication. We’re excited to see journals begin to integrate these workflows with their own publishing pipelines. For example, the Neurolibre project is deploying their own BinderHub and using it alongside their reviewing and archiving process in order to provide more rich
interaction with submitted material.
Each type of repository needs a small amount of custom work to be integrated with Binder. We started with Zenodo because it is well known,
general purpose and integrated with GitHub already. If there is an archive you’d like to see integrated please do stop by this repository and open a new issue or contribute the code to do so directly.
If you’re working with a publisher and are interested in this
please reach out! The Binder community would love to work with you in deploying these open tools to make your published work more open and accessible. Whether it is big or small, we hope that these workflows can make an impact across the publishing landscape, and we’re looking forward to seeing what people do next!

