Reproducible Data Dependencies for Python [Guest Post]

This article is the first in a series of guest blog posts about open source projects in the Jupyter ecosystem and the problems they attempt to solve. If you would like to submit a guest post to highlight a specific tool or project, please get in touch with us.
Jupyter Notebooks go a long way towards making computations reproducible and sharable. Nevertheless, for many Jupyter users, it remains a challenge to manage datasets across machines, over time, and across collaborators — especially when those datasets are large or change often. Quilt Data is a company that supports Quilt, an open source project to version and package data. The Quilt team recently released an extension for JupyterLab.
We are excited to see how the community will extend Jupyter and JupyterLab to manage datasets. Thanks to the Quilt team for submitting this guest blog post.
— The Jupyter Team
The open-source community has developed strong foundations for reproducible source code. Git supports versioning, GitHub supports collaboration. PyPI and Conda deliver code in immutable packages. Docker executes code in uniform, scalable containers.
But what about reproducible data? Data poses unique challenges: it’s larger than code, and resides in a wide variety of formats. Each data format implies different tradeoffs in serialization performance, compression, and file size. As a result, managing data becomes intractable in line-based version control systems like git. This presents a problem for Jupyter users: source code gets shared, but data gets left behind.
One solution to this problem is to port successful abstractions from source code management over to data. Versioning, packaging, and execution are well understood and universally adopted in source code management. In this article we’ll explore a collection of services that version, package, and marshal data — Quilt.
Getting data into notebooks
Notebooks that depend on data from files are fragile. File formats change, file stores move, files are copied, and file copies diverge. As a result, notebooks break as we share them across collaborators, across machines, and over time.
Quilt hides network, files, and storage behind a data package abstraction so that anyone can create durable, reproducible data dependencies for notebooks.
To run the sample code in this article, launch your favorite Python environment and install quilt:
$ pip install quiltNow we use quilt to pull data dependencies into a Jupyter notebook:
import quilt# install a small subpackage
quilt.install("uciml/heart_disease/tables/processed/switzerland", force=True)# import the data package
from quilt.data.uciml import heart_disease
In the above code, uciml/heart_disease is a data package. Packages live in repositories and have handles of the form USER/PACKAGE. The package repository includes a versioned history of the data, which we can access as follows:
In [1]: import quilt
In [2]: quilt.log("uciml/heart_disease")Hash Pushed Author
eb79ef86f84fdcf61e... 2017-06-13 19:54:44 uciml
780397900f81c3c088... 2017-06-13 19:52:21 uciml
We could install a specific version of the data by providing the hash= keyword argument to quilt.install.
Let’s access the data in our subpackage. Data are loaded into memory by adding parentheses to a package path, as follows:
heart_disease.tables.processed.switzerland()Command line and Python interfaces
Virtually all Quilt commands are available on both the command line and in Python. For example $ quilt log uciml/heart_disease in Terminal is equivalent to quilt.log("uciml/heart_disease") in Python.
What about unstructured data, like images?
In the preceding example we saw that Quilt reads columnar data into data frames. Semi-structured and unstructured data — such as JSON, images, and text — are also supported. Unstructured data skip serialization and are simply copied into Quilt’s object store. For instance if a user calls pkg.unstructured_txt() they receive a path to the unstructured file on disk, not a data frame. Future versions of Quilt will provide a wider variety of native deserializers (e.g. JSON to dict for Python).
Understanding the object store
All package data are read from Quilt’s object store. The object store provides three performance enhancements:
- deduplication — Each unique data fragment is named by its SHA-256 hash so that when Quilt users push and pull data, only the fragments that have changed are sent over the network
- fast reads of large files — the package akarve/nyc_taxi contains a 1.7GB CSV table. Quilt produces a data frame from the table in 4.88 seconds, thanks to PyArrow’s efficient handling of Parquet. By comparison,
pandas.read_csv()takes 47 seconds to produce the same data frame from its CSV source. Andpandas.read_sql()takes more than 5 minutes to acquire the same data from a database. - columnar storage — Quilt converts tabular data into Apache Parquet columns. Parquet columns can be efficiently compressed, deserialized, and searched by tools like PrestoDB and HiveSQL.
Browsing data packages in JupyterLab
As Jupyter users we want to make it easy to find and consume new data packages. Quilt leverages JupyterLab’s extension architecture to create an extension that lets you search Quilt for data packages.
If desired, switch to an environment of your choice. Next, install the Quilt extension for JupyterLab as follows (see the quilt extension repo for further documentation):
$ pip install quilt
$ pip install jupyter -U
$ pip install jupyterlab
$ jupyter labextension install jupyterlab-quilt
$ jupyter lab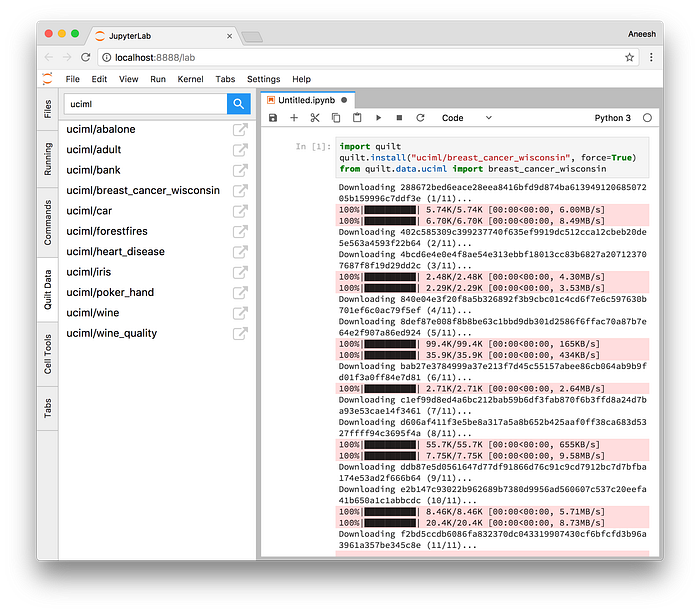
If you type “uciml” in the search box you’ll see a list of packages from the UCI Machine Learning Repository. If you click on a package in the list, the extension will generate the code to install and import the package. Click on the link icon, far right, to visit the package repository page, where you’ll find further documentation on the data.
quilt.yml is like requirements.txt for data
We can express a notebook’s data dependencies in a YAML file, conventionally called quilt.yml:
packages:
- asah/mnist
- uciml/heart_disease/tables/processed/switzerland:hash:eb79ef86
- akarve/pydata_book/titanic:tag:featuresAnyone with the above wishes to reproduce a notebook that depends on the above packages can type the following:
$ quilt install quilt.ymlJupyter notebooks on the same machine now have access to the quilt.yml-specified versions of MNIST, Titanic, and Heart Disease.
quilt.yml for Binder notebooks
If you’re running Jupyter notebooks on the web with Binder, here’s an example of how to install data dependencies in a Binder container.
Build your own data package
Let’s create a data package that contains Bitcoin prices. You can start by downloading the source data BTC_prices.csv, placing it in a clean directory, and changing to the same directory:
$ mkdir quilt-btc
$ cd quilt-btc
$ curl https://s3.amazonaws.com/quilt-web-public/data/BTC_prices.csv -o BTC_prices.csv
$ ls
BTC_prices.csvWe can use quilt generate to create a build.yml file. build.yml specifies how data are transformed into an in-memory package tree.
$ quilt generate .
Generated build-file ./build.yml.Here’s what’s in build.yml:
contents:
BTC_prices:
file: BTC_prices.csvquilt generate recursively descends a directory to include all descendants folders and files in a generated build.yml file. Quilt packages can contain thousands of files and hundreds of gigabytes of data.
Let’s modify our build.yml to specify how we want our data package to be structured. We’ll rename the node, and use kwargs to parse the Date column as a datetime, specify the quote character, and skip some comment rows.
contents:
prices:
kwargs:
parse_dates: ['Date']
quotechar: "\""
skiprows: [2714, 2715, 2716]
file: BTC_prices.csv(Behind the scenes, kwargs are handed to pandas.read_csv.)
Finally, we’ll document our data package with a README.md file:
# Bitcoin pricesThis data was produced from the [CoinDesk price page](http://www.coindesk.com/price/).
We need to add README.md to build.yml so that the Quilt compiler knows to include it in the package:
contents:
README:
file: README.md
prices:
kwargs:
parse_dates: ['Date']
quotechar: "\""
skiprows: [2714, 2715, 2716]
file: BTC_prices.csvIf you wish to upload your package you’ll need a Quilt account. You can log in to Quilt from Terminal:
$ quilt loginNow we rebuild the package to include our README and new kwargs:
$ quilt build USERNAME/PACKAGE build.ymlFinally, we publish our package to the registry so that other users can access the data:
$ quilt push USERNAME/PACKAGE --publicYour package is now live in the web catalog, like this akarve/BTC example.
quilt log USERNAME/PACKAGE shows the time and tophash for our recent push. Here’s what quilt log outputs for my package:
Hash Pushed Author
e81757c6cc6fd5ccfcd589e0b62a7d9… 2017–12–22 13:43:12 akarveAny notebooks that depend on this version of the akarve/BTC package can declare the dependency in a quilt.yml file or directly in code:
quilt.install("akarve/BTC", hash="e81757c")Alternatively, we can associate a human-readable tag with any of the hashes from quilt log.
$ quilt tag add akarve/BTC crypto e81757cAny notebooks that contain the following line of code point to the same immutable data package and are reproducible across machines:
quilt.install("akarve/BTC", tag="crypto")Where does my data live?
By default Quilt store data in the registry at quiltdata.com. Alternatively, you can host your own registry by running the open source containers, then using quilt config to point clients to your private registry.
Conclusion
We’ve explored data packages as versioned, immutable building blocks that encapsulate data dependencies. The data package lifecycle is driven by four commands: build, push, install, and import.
In the near future we plan to make the JupyterLab extension bidirectional, so that users can not only pull data from Quilt, but easily push cell data into Quilt. Support for R, Spark, and HDFS are also on the Quilt roadmap.
The Quilt compiler, registry, and catalog are open source. We welcome your contributions.

