Zero to JupyterHub helm chart 0.8
We’ve just released version 0.8 of the jupyterhub helm chart.
For those who may not know, Zero to JupyterHub is a guide and helm chart for deploying JupyterHub on Kubernetes. Helm is like a package manager for Kubernetes, which aims to make it easy to install and manage applications on your cluster.
There are loads of bugfixes and improvements to this release, and we encourage you to check out the change log. Here, we’ll discuss two highlights from the new features: profiles and autoscaling.
Profiles
By adopting the profiles pattern established in WrapSpawner, Kubernetes users can now pick from a selection of “profiles” or pre-set configurations, defined by the operator of a cluster. For example, defining small, medium, and large resource requests, or special profiles for GPUs.
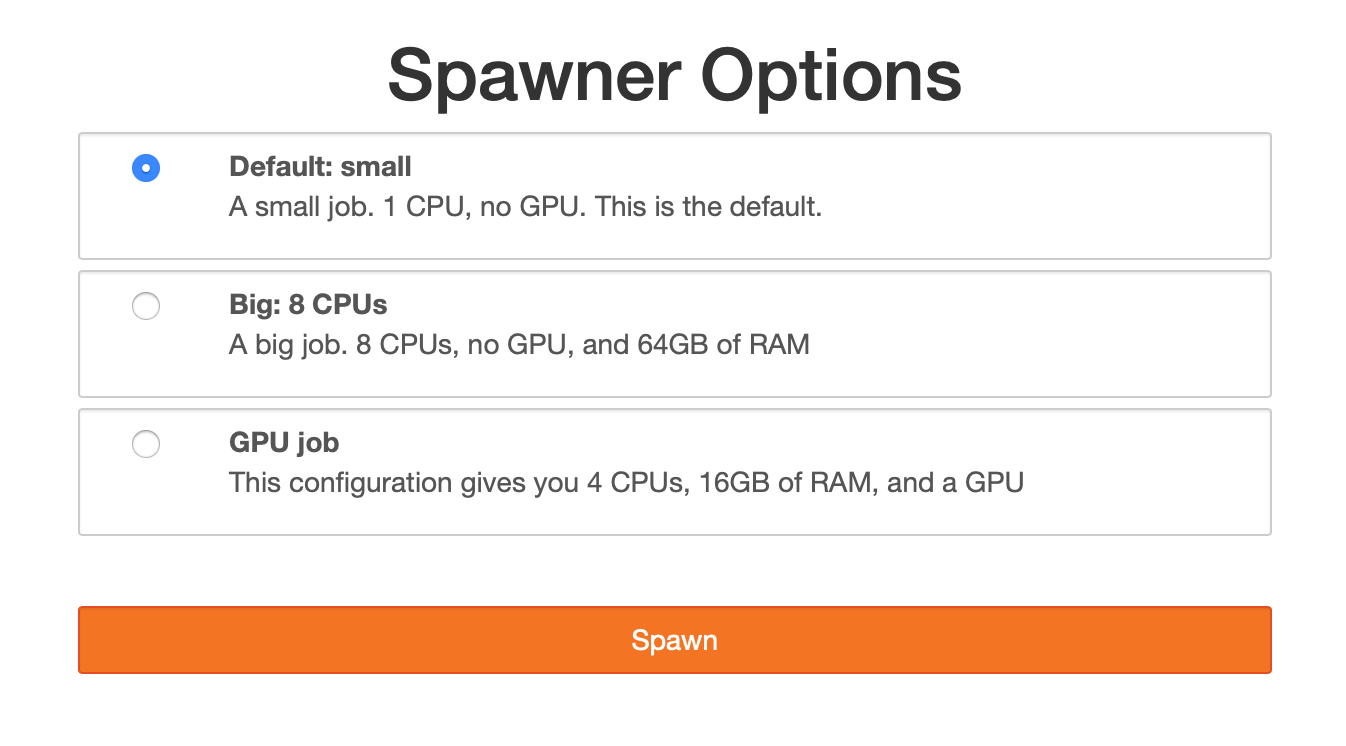
The above sample is created from the following snippet in your values.yaml:
singleuser:
profileList:
- display_name: "Small: default"
description: |
A small job. 1 CPU, no GPU. This is the default.
default: True
kubespawner_override:
cpu_limit: 1
cpu_guarantee: 1
mem_limit: "1G"
mem_guarantee: "512M"
extra_resource_limits: {}
- display_name: "Big: 8 CPUs"
description: |
A big job. 8 CPUs, no GPU, and 64GB of RAM
kubespawner_override:
cpu_limit: 8
cpu_guarantee: 8
mem_limit: "64G"
mem_guaranttee: "64G"
extra_resource_limits: {}
- display_name: "GPU job"
description: |
This configuration gives you 4 CPUs, 16GB of RAM, and a GPU
kubespawner_override:
image: consideratio/singleuser-gpu:v0.3.0
cpu_limit: 4
cpu_guarantee: 4
mem_limit: "16G"
mem_guarantee: "16G"
extra_resource_limits:
nvidia.com/gpu: "1"Autoscaling
Autoscaling is a big focus of this release, and many of the new features in 0.8 of the chart relate to scaling in some way. At the center is a new ‘user scheduler’ a custom kubernetes scheduler responsible for assigning user pods to nodes. To enable the user scheduler:
scheduling:
userScheduler:
enabled: trueThere are two major pain-points for autoscaling with JupyterHub. First, is scaling up. Kubernetes scale-up is very basic: If scheduling a pod fails due insufficient resources, a new node is requested. This isn’t a great fit for JupyterHub. If you happen to be the unlucky user who is the first to need a new node, launching your server can take several minutes as the new node is requested and warming up. To prevent this, the chart adds the notion of “placeholder pods,” which are pods that request the same resources as user pods, but have lower priority and will thus be evicted immediately if a user pod needs their resources. This allows a cluster to always have a certain amount of “headroom” of vacant slots available for users so that requesting a new node occurs not when there are 0 slots available for users, but instead when there are 5 or 10 (you choose) slots available. See this exploration of how mybinder.org arrived at 25 placeholders for its deployment. To enable 10 user placeholders:
scheduling:
podPriority:
enabled: true
userPlaceholder:
enabled: true
replicas: 10The second major improvement to autoscaling that comes with the user scheduler is in scaling down. If your cluster is automatically scaling up, you probably want it to scale down as well when you no longer need the added capacity. Unfortunately, because user pods cannot be kicked out, Kubernetes’ default scheduler doesn’t manage to drain nodes that are no longer needed without some manual intervention. The user scheduler adds this feature, ensuring that, over time, your newest nodes eventually drain when they are no longer needed. It accomplishes this by prioritizing the node with the most other user pods when picking a node to start new users. If there is an extra node, over time eventually all the users on that node will stop and the node will become idle and culled by the cluster autoscaler. This is the default behavior . There’s loads more scheduling optimizations available in the updated documentation, including dedicating certain nodes to users so that user pods never run on the same node as others, etc.
And finally, a huge thanks to the numerous contributors who helped make this release, be it via documentation contributions, testing, discussion, or code.
